- Úvod do témy: Prečo je Iterator Vzor kľúčový pre FinTech?
- Čo je Iterator Vzor a jeho Základné Princípy v Java programovaní?
- Výhody Iterator Vzoru pre Efektívne Prechádzanie Finančných Dát
- Implementácia Iterator Vzoru v Jave pre Finančné Dátové Štruktúry
- Praktické Aplikácie a Scenáre Použitia vo FinTech Analýze
- Výzvy a Riešenia pri Používaní Iteratora s Komplexnými Finančnými Dátami
- Často kladené otázky
Úvod do témy: Prečo je Iterator Vzor kľúčový pre FinTech?
V dynamickom svete finančných technológií, kde sa objemy dát neustále zvyšujú a požiadavky na ich spracovanie sú čoraz komplexnejšie, sa stáva efektívna manipulácia s informáciami absolútne nevyhnutnou. Od spracovania transakcií, cez analýzu trhových dát až po správu portfólií, vývojári neustále hľadajú spôsoby, ako zjednodušiť prístup k dátam a zároveň zabezpečiť ich integritu a výkon. V tomto kontexte sa Iterator vzor javí ako neoceniteľný návrhový vzor, ktorý prináša eleganciu a robustnosť do programovania Java, najmä pri práci s rôznorodými Java dátovými štruktúrami.
Tento článok sa ponorí do hĺbky Iterator vzoru a ukáže, ako môže transformovať spôsob, akým pristupujeme k finančným dátam. Zameriame sa na jeho základné princípy, výhody a praktické aplikácie v oblasti FinTech. Pochopenie a správne využitie tohto vzoru môže viesť k výraznému zlepšeniu prehľadnosti kódu, zjednodušeniu údržby a zvýšeniu celkovej efektívnosti systémov, ktoré spracovávajú obrovské objemy citlivých finančných informácií.
Čo je Iterator Vzor a jeho Základné Princípy v Java programovaní?
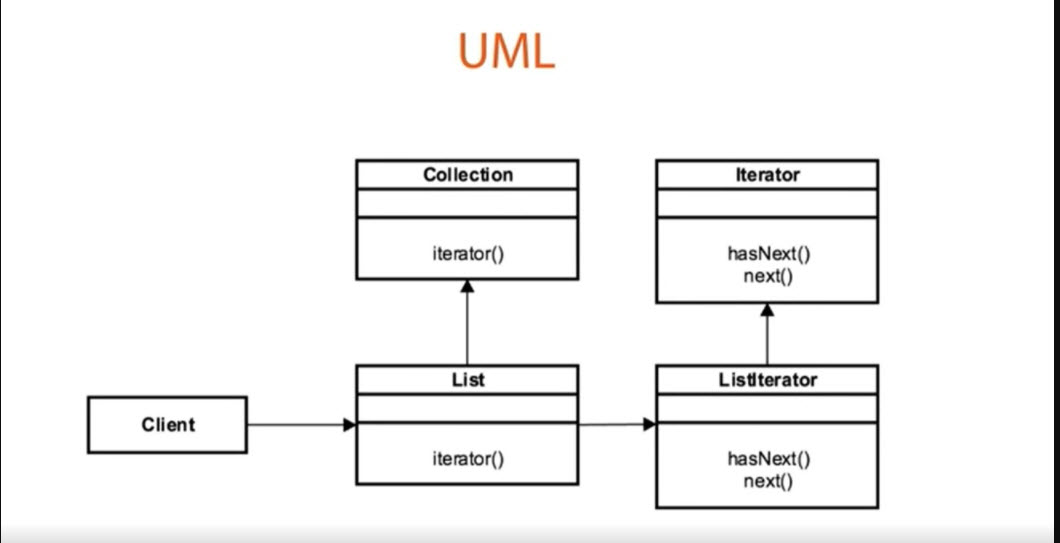
Iterator vzor je jedným z najpoužívanejších návrhových vzorov v objektovo orientovanom programovaní Java. Jeho hlavným cieľom je poskytnúť sekvenčný prístup k prvkom dátovej kolekcie bez odhalenia jej vnútornej reprezentácie. Predstavte si, že máte v banke účty rôzneho typu – sporiace, bežné, investičné. Namiesto toho, aby ste museli vedieť, ako sú tieto účty interne uložené (či už v poli, zozname alebo hash mape), Iterator vzor vám umožní prechádzať nimi jeden po druhom, akoby ste listovali v zozname, bez ohľadu na podkladovú štruktúru. Toto oddelenie logiky prechádzania od samotnej dátovej štruktúry je kľúčové pre dosiahnutie prehľadnosti kódu a flexibility.
V podstate Iterator vzor definuje dve hlavné komponenty: agregát (kolekciu dát, ktorá je iterovateľná) a samotný iterátor. Agregát poskytuje metódu na vytvorenie iterátora, zatiaľ čo iterátor poskytuje metódy ako hasNext() na kontrolu, či sú ďalšie prvky, a next() na získanie ďalšieho prvku. V Jave sú tieto koncepty abstrahované rozhraniami Iterable a Iterator, čo značne zjednodušuje ich implementáciu a použitie. Používanie týchto štandardných rozhraní zaručuje konzistentnosť a umožňuje plynulé hromadné spracovanie dát naprieč rôznymi typmi Java dátových štruktúr.
Principiálne, Iterator vzor podporuje princíp "single responsibility", keďže logika prechádzania je oddelená od logiky samotnej dátovej štruktúry. To zlepšuje modulárnosť a znižuje závislosti, čo je obzvlášť dôležité v komplexných FinTech systémoch, kde sú finančné dáta často uložené v zložitých a heterogénnych formátoch.
Výhody Iterator Vzoru pre Efektívne Prechádzanie Finančných Dát
Použitie Iterator vzoru prináša množstvo výhod, ktoré sú obzvlášť cenné v oblasti finančných technológií. Jednou z najvýznamnejších je abstrahovanie prístupu k prvkom dátovej kolekcie. V prostredí FinTech, kde sa môžu finančné dáta nachádzať v rôznych formátoch – od relačných databáz, cez NoSQL databázy až po streamingové platformy – Iterator vzor poskytuje jednotné rozhranie pre ich prechádzanie. To znamená, že vývojári nemusia písať špecifický kód pre každý typ úložiska, čo výrazne znižuje zložitosť a zvyšuje prehľadnosť kódu.
Ďalšou kľúčovou výhodou je podpora pre viaceré súbežné prechádzania. Predstavte si, že potrebujete vykonať viacero analýz nad rovnakým súborom transakcií – napríklad jednu pre výpočet celkového objemu a druhú pre identifikáciu podvodných aktivít. Bez Iterator vzoru by ste museli klonovať dátovú štruktúru alebo implementovať komplexné mechanizmy pre sledovanie pozície každého prechádzania. S iterátorom môže každá analýza získať svoj vlastný iterátor a prechádzať dátami nezávisle, čo výrazne zvyšuje efektívnosť a zjednodušuje hromadné spracovanie.
V neposlednom rade, Iterator vzor zvyšuje flexibilitu a rozširiteľnosť. Ak sa v budúcnosti zmení vnútorná reprezentácia finančných dát (napríklad prejdete z ArrayListu na LinkedList alebo inú vlastnú Java dátovú štruktúru), klienti, ktorí používajú iterátor, nebudú musieť meniť svoj kód. Ich závislosť je na abstraktnom rozhraní iterátora, nie na konkrétnej implementácii kolekcie. Táto vlastnosť je nesmierne dôležitá pre dlhodobú udržateľnosť a adaptabilitu FinTech systémov v neustále sa meniacom technologickom prostredí. Pre viac informácií o technológiách vo finančníctve navštívte kategóriu Technológie na FinTechHub.sk.
Implementácia Iterator Vzoru v Jave pre Finančné Dátové Štruktúry
Implementácia Iterator vzoru v Jave je vďaka zabudovaným rozhraniam java.lang.Iterable a java.util.Iterator pomerne priamočiara. Pre naše účely si predstavme, že máme vlastnú Java dátovú štruktúru nazvanú PortfólioTransakcií, ktorá uchováva objekty Transakcia. Každá Transakcia by mohla obsahovať detaily ako dátum, typ (nákup/predaj), symbol aktíva, množstvo a cena. Cieľom je umožniť jednoduché prechádzanie týmito transakciami bez odhalenia, či sú uložené v internom poli, zozname alebo inej štruktúre.
Naša trieda PortfólioTransakcií bude musieť implementovať rozhranie Iterable. To znamená, že musí poskytnúť metódu iterator(), ktorá vráti inštanciu Iterator. Táto interná trieda, alebo anonymná trieda v rámci PortfólioTransakcií, bude zodpovedná za uchovávanie aktuálnej pozície a poskytovanie metód hasNext() a next(). Takýmto prístupom zabezpečíme, že klienti, ktorí chcú analyzovať finančné dáta z portfólia, budú pracovať výhradne s rozhraním Iterator, čím sa dosiahne vysoká úroveň abstrakcie a prehľadnosti kódu.
Pre ilustráciu, ak by sme mali interný ArrayList v triede PortfólioTransakcií, implementácia metódy iterator() by mohla jednoducho vrátiť iterátor tohto ArrayListu. Ak by však vnútorná štruktúra bola komplexnejšia (napr. vlastná implementácia spojeného zoznamu alebo stromu), museli by sme si napísať vlastnú logiku iterátora, ktorá by navigovala cez túto špecifickú štruktúru. Práve v takýchto prípadoch sa ukazuje sila Iterator vzoru – umožňuje nám zmeniť vnútornú štruktúru bez ovplyvnenia kódu, ktorý ju používa na iteráciu. To prispieva k robustnosti a efektívnosti celého systému pre FinTech analýzu.
Praktické Aplikácie a Scenáre Použitia vo FinTech Analýze
Iterator vzor nájde široké uplatnenie v rôznych oblastiach FinTech analýzy, kde je potrebné efektívne prechádzať a spracovávať veľké objemy finančných dát. Jedným z bežných scenárov je hromadné spracovanie transakcií. Predstavte si systém, ktorý musí každý deň spracovať milióny bankových transakcií za účelom detekcie podvodov, výpočtu poplatkov alebo generovania reportov. Použitím iterátora je možné prechádzať cez tok transakcií bez načítania všetkých dát do pamäte naraz, čo šetrí zdroje a zvyšuje výkon, najmä pri práci s dátami, ktoré sa nezmestia do operačnej pamäte.
Ďalšou praktickou aplikáciou je analýza trhových dát. Algoritmické obchodné platformy neustále monitorujú ceny aktív, objemy obchodov a ďalšie ukazovatele. Tieto dáta sú často doručované ako stream. Iterator vzor umožňuje spracovávať tieto streamy dát postupne, čo je kľúčové pre real-time analýzu a rýchle rozhodovanie. Namiesto práce s celou históriou dát sa iterátor posúva po jednotlivých dátových bodoch, čím sa minimalizuje latencia a zaručuje sa aktuálnosť informácií. Pre záujemcov o investovanie a krypto, odporúčame navštíviť Investovanie alebo Krypto.
V oblasti správy portfólií sa iterátor využíva na prechádzanie rôznymi typmi aktív – akciami, dlhopismi, kryptomenami alebo komoditami – uloženými v komplexných Java dátových štruktúrach. Umožňuje napríklad ľahko vypočítať celkovú hodnotu portfólia, identifikovať aktíva s najvyššou volatilitou alebo generovať personalizované prehľady pre klientov. Vďaka Iterator vzoru je možné efektívne agregovať a analyzovať finančné dáta z heterogénnych zdrojov, čo prispieva k lepšiemu finančnému rozhodovaniu a celkovej efektívnosti systémov. Zvyšuje sa tým aj prehľadnosť kódu, pretože logika spracovania dát je oddelená od spôsobu ich uloženia.
Výzvy a Riešenia pri Používaní Iteratora s Komplexnými Finančnými Dátami
Aj keď Iterator vzor prináša značné výhody, jeho implementácia a efektívne využitie s komplexnými finančnými dátami môže priniesť určité výzvy. Jednou z hlavných je správa stavu iterátora, najmä pri hromadnom spracovaní a súbežných operáciách. Ak sa napríklad iteruje cez transakcie a počas iterácie dôjde k zmene podkladovej dátovej kolekcie (pridanie alebo odstránenie transakcie), môže to viesť k takzvaným "concurrent modification" výnimkám. V Jave sú štandardné implementácie iterátorov (napr. pre ArrayList) "fail-fast", čo znamená, že rýchlo detekujú takéto zmeny a vyhodia výnimku, čím pomáhajú predchádzať nekonzistentnému správaniu.
Riešením pre túto výzvu je buď synchronizácia prístupu k dátovej štruktúre počas iterácie, alebo použitie "copy-on-write" stratégií, kde sa vytvorí kópia dát pre iterátor, čím sa zabezpečí jeho izolácia od zmien. Pri FinTech analýze, kde je integrita dát kľúčová, je často preferovanou možnosťou vytvorenie nemenného snímku dát pre iteráciu. To môže síce zvýšiť spotrebu pamäte, ale zaručuje konzistentnosť výsledkov. Ďalšou výzvou je výkon pri iterácii cez extrémne veľké finančné dáta s miliónmi alebo miliardami záznamov. V takýchto prípadoch je dôležité optimalizovať internú implementáciu iterátora tak, aby minimalizoval alokácie pamäte a maximalizoval rýchlosť prístupu k dátam. Tu prichádza do úvahy aj lazy loading, kedy iterátor načítava dáta po častiach, len keď sú potrebné, čo znižuje požiadavky na pamäť.
Okrem toho, pri práci s distribuovanými systémami alebo dátovými streamami, kde finančné dáta nie sú uložené centrálne, ale prichádzajú postupne, je potrebné adaptovať Iterator vzor na asynchrónne spracovanie. To môže zahŕňať použitie reaktívnych prúdov (reactive streams) alebo špeciálnych asynchrónnych iterátorov, ktoré dokážu spracovávať dáta, akonáhle sú dostupné, bez blokovania hlavného vlákna. Tieto pokročilé techniky prispievajú k celkovej efektívnosti a robustnosti systémov, ktoré spracovávajú rozsiahle dátové kolekcie vo finančnom sektore.
Pokročilé Aspekty a Rozšírenia Iterator Vzoru pre Zložitú FinTech Analýzu
Pre sofistikovanú FinTech analýzu je často potrebné rozšíriť základný Iterator vzor o pokročilé funkcionality. Jedným z takých rozšírení je filtrovanie alebo transformácia dát počas iterácie. Namiesto toho, aby sme vytvorili novú dátovú kolekciu pre filtrované dáta, môžeme implementovať "filtrovací iterátor", ktorý bude obalovať pôvodný iterátor a vracať len prvky spĺňajúce určité kritériá (napr. transakcie nad určitou sumou alebo len nákupy). Týmto sa zvyšuje efektívnosť, pretože sa vyhýbame zbytočnej alokácii pamäte a prechádzame dátami len raz.
Ďalším pokročilým aspektom je "kompozitný iterátor", ktorý umožňuje iterovať cez prvky z viacerých podkladových Java dátových štruktúr, akoby boli jednou. Napríklad, ak banka uchováva transakcie v rôznych databázach podľa regiónu, kompozitný iterátor by mohol poskytnúť jednotný pohľad na všetky transakcie bez ohľadu na ich pôvod. Táto technika je obzvlášť užitočná pri agregácii finančných dát z heterogénnych zdrojov a prispieva k lepšej prehľadnosti kódu, pretože logika integrácie je abstrahovaná v iterátore.
V modernom programovaní Java a najmä s príchodom Java 8 Streams API, sa koncept iterátora posunul na novú úroveň. Streams poskytujú deklaratívny spôsob spracovania dátových kolekcií, ktorý je založený na iterátoroch, ale abstrahuje mnoho nízkoúrovňových detailov. Aj keď Streams API ponúka výkonné nástroje pre paralelizáciu a lenivé vyhodnocovanie, pod jeho kapotou stále pracuje Iterator vzor. Pre vývojárov to znamená, že pochopenie základných princípov iterátora je stále kľúčové pre efektívne využitie moderných API a pre optimalizáciu výkonu pri hromadnom spracovaní.
Budúcnosť Iteratora vo FinTech: Viac než Len Prechádzanie Dát
Budúcnosť Iterator vzoru vo FinTech presahuje jednoduché prechádzanie dátových kolekcií. S rastúcim dôrazom na real-time spracovanie, analýzu veľkých dát (Big Data) a umelú inteligenciu, sa iterátor stáva základným kameňom pre budovanie adaptívnych a škálovateľných systémov. Jedným z kľúčových trendov je integrácia iterátorov s distribuovanými výpočtovými frameworkmi, ako sú Apache Spark alebo Apache Flink. Tieto platformy používajú interné mechanizmy podobné iterátorom na spracovanie masívnych objemov finančných dát distribuovaným spôsobom, čo umožňuje efektívnosť, ktorá by bola s tradičnými metódami nedosiahnuteľná.
Ďalším dôležitým smerom je využitie iterátorov v kontexte dátovej lineage a auditu. V regulovanom finančnom prostredí je nevyhnutné vedieť, odkiaľ finančné dáta pochádzajú, ako boli spracované a kto k nim mal prístup. Iterátory, ktoré sledujú pôvod a transformácie dát, môžu výrazne zjednodušiť auditné procesy a zabezpečiť súlad s reguláciami. Predstavte si iterátor, ktorý nielen prechádza transakciami, ale zároveň zaznamenáva, ktorá analytická operácia bola na každej transakcii vykonaná. Tým sa zvyšuje transparentnosť a spoľahlivosť systémov.
Napokon, s rozvojom decentralizovaných financií (DeFi) a blockchainových technológií, bude Iterator vzor zohrávať úlohu pri prechádzaní záznamov v distribuovaných knihách (ledgers). Iterovanie cez bloky transakcií na blockchaine, hľadanie konkrétnych smart kontraktov alebo overovanie konsenzu si vyžiada robustné a výkonné iterátory. Tieto aplikácie zdôrazňujú univerzálnosť a adaptabilitu tohto návrhového vzoru. Pre viac informácií o budúcnosti financií a inováciách navštívte kategóriu Osobné Financie na FinTechHub.sk, kde nájdete aj články o vplyve technológií.
Často kladené otázky
Prečo je Iterator vzor dôležitý vo FinTech?
Iterator vzor je kľúčový vo FinTech, pretože umožňuje efektívne prechádzanie a spracovanie rozsiahlych a komplexných finančných dátových štruktúr bez odhalenia ich vnútornej implementácie. Zvyšuje prehľadnosť kódu, flexibilitu, podporuje hromadné spracovanie a uľahčuje údržbu systémov, ktoré musia pracovať s neustále rastúcimi objemami dát.
Aký je rozdiel medzi Iterable a Iterator v Jave?
Rozhranie Iterable definuje metódu iterator(), ktorá vráti inštanciu Iterator. Trieda, ktorá implementuje Iterable, je "iterovateľná", čo znamená, že je možné ju prechádzať pomocou iterátora. Samotné rozhranie Iterator definuje metódy ako hasNext() (pre kontrolu, či je ďalší prvok) a next() (pre získanie ďalšieho prvku), ktoré slúžia na samotné prechádzanie dátovou kolekciou.
Môže Iterator vzor pomôcť pri spracovaní dát v reálnom čase (real-time data processing)?
Áno, Iterator vzor je veľmi užitočný pre spracovanie dát v reálnom čase, najmä pri práci s dátovými streamami. Umožňuje postupne spracovávať prichádzajúce finančné dáta (napr. trhové ceny alebo transakcie) bez nutnosti načítania celého datasetu do pamäte. Tým sa minimalizuje latencia a systémy môžu reagovať na zmeny takmer okamžite, čo je kritické pre FinTech analýzu.
Aké sú potenciálne nevýhody použitia Iteratora?
Potenciálne nevýhody zahŕňajú problémy so synchronizáciou pri súbežných modifikáciách podkladovej dátovej kolekcie počas iterácie, čo môže viesť k výnimkám. Ďalšou výzvou môže byť manažment pamäte pri vytváraní snímok dát pre iteráciu z veľmi rozsiahlych finančných dát. Tieto výzvy sa však dajú riešiť vhodnými návrhovými vzormi a technikami programovania Java, ako sú synchronizácia, "copy-on-write" alebo lazy loading.
Ako súvisí Iterator vzor s Java Streams API?
Java Streams API, predstavené v Java 8, je postavené na základoch Iterator vzoru. Streamy poskytujú vyššiu úroveň abstrakcie pre spracovanie dátových kolekcií, umožňujúc deklaratívne a funkcionálne operácie. Hoci vývojári priamo nepracujú s rozhraním Iterator pri použití Streamov, mechanizmus prechádzania a spracovania dát pod kapotou Streams API stále využíva princípy iterátora, čo zabezpečuje jeho efektívnosť a flexibilitu pri hromadnom spracovaní.